ΜΕ ΤΟ CHATGPT ΚΑΤΑΛΑΒΑΙΝΟΥΜΕ ΓΙΑΤΙ Ο ΑΝΘΡΩΠΟΣ ΓΙΝΕΤΑΙ ΠΕΡΙΤΤΟΣ ΣΤΗΝ ΕΡΓΑΣΙΑ
Το ChatGPT μπορεί να αντικαταστήσει ήδη εργαζομένους σε τρεις τομείς, να γράψει εκθέσεις μαθητών, να συνθέσει τραγούδια και να σου μιλάει. Σαν άνθρωπος. Πώς λειτουργεί το τελειότερο chatbot.
Κάθε φορά που λαμβάνεις άμεση απάντηση, σε μήνυμα που στέλνεις σε chat εξυπηρέτησης πελατών εταιρίας (σε οργανισμό, φορέα τομέων όπως το εμπόριο, η εκπαίδευση, η ψυχαγωγία, τα οικονομικά, η υγεία, οι ειδήσεις και η παραγωγικότητα) αναλαμβάνει δράση ένα chatbot, που έχει ‘εκπαιδευτεί’ για να μη νιώθεις πως σε αγνοούν.
Την ίδια ώρα, ο παραλήπτης κερδίζει χρόνο μέχρι και δίνει μια ανάσα στα -υποστελεχωμένα συνήθως- τμήματα.
Η εφαρμογή λογισμικού “που χρησιμοποιείται για τη διεξαγωγή μιας διαδικτυακής συνομιλίας μέσω κειμένου ή μετατροπής κειμένου σε ομιλία, αντί για την παροχή άμεσης επαφής με έναν ζωντανό ανθρώπινο παράγοντα” σχεδιάζεται από ανθρώπους, ώστε να προσομοιώνουν πειστικά τον τρόπο με τον οποίο θα συμπεριφερόταν ένας κανονικός (ανθρώπινος) συνομιλητής.
Οι ‘δάσκαλοι’ φροντίζουν να καταχωρούν διαρκώς ό,τι μπορεί να ζητηθεί από το κοινό, ώστε να μην υπάρχουν ‘κενά’. Αυτό δεν είναι βέβαια, κάτι που ‘πετυχαίνουν’ όλοι.
Προφανώς και δεν είναι όλα τα chatbots ίδια.
Ορισμένα χρησιμοποιούν εκτεταμένες διαδικασίες ταξινόμησης λέξεων, επεξεργαστές φυσικής γλώσσας και εξελιγμένο AI. Άλλα κάνουν μια απλή, ταπεινή, ‘σάρωση’ γενικών λέξεων που έχουν δοθεί ως ‘κλειδιά’. Δίνουν απαντήσεις που ‘βρίσκουν’ σε συσχετισμένη ‘βιβλιοθήκη’ ή βάση δεδομένων.
Το ChatGPT (Chat Generative Pre-trained Transformer) κυκλοφορεί ως το chatbot που θα κάνει ξεπερασμένο το Google. Ήδη συγκρίνεται με το iPhone ο πιθανός αντίκτυπος του στην κοινωνία.
Γιατί;
Σήμερα που μιλάμε (λίγους μήνες μετά την εμφάνιση του στη ζωή μας) μπορεί να αντικαταστήσει ανθρώπους που ασχολούνται με το αρχικό επίπεδο του copywriting, του προγραμματισμού (βοηθά ήδη επαγγελματίες να εντοπίσουν λάθη σε κώδικες και να τα διορθώσουν) και της εξυπηρέτησης πελατών.
Παρεμπιπτόντως, μπορεί να συνθέσει και μουσική, να γράψει κείμενα και εκθέσεις μαθητών.
Δεν έχει τελειοποιηθεί ακόμα ως σύστημα, εν τούτοις σε αυτά που το κάνουν ήδη μοναδικό είναι ότι δεν ξεχνάει τις ‘συζητήσεις’ που έχουν προηγηθεί.
Για αυτούς και πολλούς άλλους λόγους που θα δούμε στη συνέχεια, έχει χαρακτηριστεί μεν ως ‘εντυπωσιακό’, αλλά και επικίνδυνο.
Από την Eliza στον αλγόριθμο που “κοροϊδεύει” τους ανθρώπους που το έφτιαξαν
Να σου πω όμως, πώς ξεκίνησαν όλα πριν 56 χρόνια. Ο Joseph Weizenbaum ήταν καθηγητής της επιστήμης των υπολογιστών στο Massachusetts Institute of Technology (ΜΙΤ), όταν σκέφτηκε πως ήθελε να δημιουργήσει ένα πρόγραμμα, το οποίο να κάνει ξεκάθαρη την επιπολαιότητα της επικοινωνίας μεταξύ των μηχανών και των ανθρώπων.
Άρχισε να δουλεύει στο πρώιμο παράδειγμα πρωτόγονης επεξεργασίας φυσικής γλώσσας Offsite το 1964. Δυο χρόνια μετά παρουσίασε την Eliza (το ‘δανείστηκε’ από τον Πυγμαλίων του Μπερνάρ Σο). Ήταν η πρώτη ψυχοθεραπεύτρια τεχνητής νοημοσύνης και το πρώτο -γνωστό- πρόγραμμα chatterbot.
Μπορείς να δοκιμάσεις και να διαπιστώσεις πώς ‘δούλευε’.
Το πρόγραμμα λειτουργούσε με την επεξεργασία των απαντήσεων των χρηστών σε σενάρια, το πιο γνωστό από τα οποία ήταν το DOCTOR: ήταν ικανό να εμπλέξει ανθρώπους σε μια συνομιλία που έμοιαζε εντυπωσιακά με συνομιλία ψυχολόγου που έχει ενσυναίσθηση, με ασθενή.
Ο προγραμματιστής μοντελοποίησε το στιλ συνομιλίας σύμφωνα με τον Carl Rogers, ο οποίος εισήγαγε τη χρήση ερωτήσεων ανοιχτού τύπου για να ενθαρρύνει τους ασθενείς να επικοινωνούν πιο αποτελεσματικά με τους θεραπευτές τους.
Το πρόγραμμα εφάρμοσε κανόνες αντιστοίχισης προτύπων σε δηλώσεις, για να υπολογίσει τις απαντήσεις του.
Χωρίς να χρησιμοποιεί παρά ελάχιστες πληροφορίες για την ανθρώπινη σκέψη ή συναίσθημα, ο DOCTOR μερικές φορές παρείχε μια εκπληκτικά ανθρώπινη αλληλεπίδραση.
Το αποτέλεσμα οδήγησε τον επιστήμονα στο να σκεφτεί φιλοσοφικά τις επιπτώσεις της τεχνητής νοημοσύνης και, αργότερα, να γίνει επικριτής της.
Μισό και πλέον αιώνα αργότερα, τα chatbots είναι μέρος της καθημερινότητας μας. Κάποια παραμένουν τραγικά, σε αποτελεσματικότητα.
Το ChatGPT έχει χαρακτηριστεί ως το πιο έξυπνο και πιο ευέλικτο της ιστορίας, καθώς μπορεί να αστειευτεί, να σε ‘κρατήσει’ σε μια συζήτηση και να γράψει τις εκθέσεις που βαριέσαι να κάνεις. Μπορεί να δώσει ιατρικές διαγνώσεις, να εξηγήσει πολύπλοκες επιστημονικές έννοιες και… εν πάση περιπτώσει να γίνει πολύ φίλος σου.
Ίσως ο καλύτερος φίλος σου, αφού αναγνωρίζει και τα λάθη του.
Όπως αναφέρουν οι δημιουργοί του “εκπαιδεύσαμε ένα μοντέλο που ονομάζεται ChatGPT, το οποίο αλληλεπιδρά με συνομιλητικό τρόπο. Η μορφή διαλόγου επιτρέπει στο ChatGPT να απαντά σε επακόλουθες ερωτήσεις, να παραδέχεται τα λάθη του, να αμφισβητεί λανθασμένες εγκαταστάσεις και να απορρίπτει ακατάλληλα αιτήματα”.
Η εκπαίδευση του ChatGPT έγινε με τη χρήση της Ενισχυτικής Μάθησης από Ανθρώπινη Ανάδραση (Reinforcement Learning from Human Feedback -RLHF).
Περί τίνος πρόκειται;
Κοντολογίς, όσα σου λέει το ChatGPT είναι συνθέσεις από δισεκατομμύρια παραδείγματα ανθρώπινης γνώμης (αντιπροσωπεύουν κάθε πιθανή άποψη), που κρίνει πως είναι οι σωστές.
Κατά τους New York Times το ChatGPT έχει προγραμματιστεί για να απορρίπτει ‘ακατάλληλα αιτήματα’ που έχουν να κάνουν κυρίως, με παράνομες δραστηριότητες. Ναι, χρήστες έχουν βρει ‘παρακαμπτηρίους’ ήδη -πχ αναδιατυπώνουν το αίτημα ως υποθετικό σκεπτικό πείραμα και ζητούν τη συγγραφή σκηνής για έργο. Άλλοι δίνουν εντολή στο bot να απενεργοποιήσει τα χαρακτηριστικά ασφαλείας που διαθέτει.
Είπαμε: δεν είναι τέλειο. Οι δημιουργοί του βέβαια, έχουν υποσχεθεί πως δεν θα σταματήσουν έως ότου φτάσουν στο άριστο.
Ο στόχος της δημιουργίας μηχανής που θα σκέφτεται όπως το ανθρώπινο μυαλό
H OpenAI -όπου ανήκει το ChatGPT- είναι ανεξάρτητος οργανισμός που ιδρύθηκε το Δεκέμβριο του 2015 στο San Francisco από τους Sam Altman, Elon Musk και άλλους θιασώτες της τεχνολογίας.
Διέθεσαν 1.000.000.000 δολάρια στο ερευνητικό εργαστήριο τεχνητής νοημοσύνης που είχε ως λόγο ύπαρξης την έρευνα στον τομέα της Artificial Intelligence, με στόχο τη δημιουργία του AGI.
Δηλαδή, της μηχανής με τις μαθησιακές και συλλογιστικές δυνάμεις ενός ανθρώπινου μυαλού.
Ο Musk παραιτήθηκε το 2018 από το διοικητικό συμβούλιο, εν τούτοις παραμένει υποστηρικτής. Ο -θρυλικός τεχνολογικός επενδυτής- Altman είναι CEO του οργανισμού.
Το 2019 η OpenAI έλαβε επένδυση 1 δισεκατομμυρίου δολαρίων από τη Microsoft και την Matthew Brown Companies και σήμερα είναι εκ των κορυφαίων του είδους του -χάριν στην πρωτότυπη έρευνα που κάνει και όσα έχει ήδη ανακαλύψει.
Επειδή θα μαζευτούν πολλές άγνωστες ‘λέξεις’ θα χρειαστώ την υπομονή σου, για να τις δούμε όλες -και να καταλάβουμε τι συμβαίνει.
Η OpenAI θέλει μεν, να φτιάξει την πρώτη μηχανή που θα σκέφτεται όπως ο άνθρωπος, εν τούτοις δεν θέλει να καταστρέψει και τον κόσμο και για αυτό έχει ορκιστεί να κάνει τα πάντα “για να διασφαλίσουμε πως η τεχνολογία αναπτύσσεται με ασφάλεια και ότι τα οφέλη της διανέμονται ομοιόμορφα στον κόσμο”.
Ο χρόνος βέβαια, είναι αυτός που θα δείξει την αλήθεια. Σε κάθε περίπτωση, θα ήθελα να ξέρεις πως την ίδια αποστολή έχει και η DeepMind που από το 2014 ανήκει στην Google.
Δεν είναι ‘εχθροί’, αλλά συνεργάτες, όπως απέδειξαν με την σύμπραξη τους για την ανάπτυξη αλγόριθμου που μπορεί να συμπεράνει τι θέλουν οι άνθρωποι -επιλέγοντας ποια από τις δύο προτεινόμενες συμπεριφορές είναι καλύτερη.
Αυτό είναι το Reinforcement Learning from Human Feedback.
Πώς εκπαιδεύτηκε το ‘τελειότερο chatbot της αγοράς’
Οι άνθρωποι που ‘έφτιαξαν’ το ChatGPT το εκπαίδευσαν με το RLHF. Κατά τους δημιουργούς του “ένα βήμα προς την οικοδόμηση ασφαλών συστημάτων τεχνητής νοημοσύνης, είναι να καταργηθεί η ανάγκη για να γράφουν οι άνθρωποι λειτουργίες στόχου” μεταξύ άλλων.
Ο αλγόριθμος εκμάθησης RLHF χρησιμοποιεί ‘μικρές ποσότητες’ ανθρώπινης ανατροφοδότησης για την επίλυση σύγχρονων περιβαλλόντων Reinforcement Learning (RL).
Το RL είναι ισχυρή κατηγορία Μηχανικής Εκμάθησης (Machine Learning), που σε αντίθεση με την εποπτευόμενη μάθηση (άλλη ‘δυνατή’ κατηγορία), δεν απαιτεί data labeling για να εκπαιδεύσει μια μηχανή ή έναν agent, ώστε να λαμβάνει έξυπνες αποφάσεις.
Το data labeling είναι διαδικασία αναγνώρισης ακατέργαστων δεδομένων -εικόνες, αρχεία κειμένου, βίντεο κλπ- και προσθήκη μιας ή περισσότερων ενημερωτικών labels για να ‘προκύψει’ το περιεχόμενο από το οποίο θα ‘μάθει’ ο υπολογιστής.
Το Reinforcement Learning περιστρέφεται γύρω από μόνο δύο στοιχεία:
- το περιβάλλον (ο κόσμος προσομοίωσης με τον οποίον αλληλεπιδρά η μηχανή -agent) και
- ο agent (ρομπότ, υπολογιστής κλπ που εκπαιδεύεται από τον αλγόριθμο RL για να δρα ανεξάρτητα και έξυπνα).
Τα συστήματα μηχανικής μάθησης με ανθρώπινη ανατροφοδότηση έχουν διερευνηθεί στο παρελθόν, αλλά η OpenAI με την DeepMind έφτασαν τον αλγόριθμο τους στο σημείο που να μπορεί να διαχειρίζεται πολύ πιο περίπλοκες εργασίες.
“Ο αλγόριθμός μας χρειαζόταν 900 bits ανατροφοδότησης από έναν ανθρώπινο αξιολογητή για να μάθει να κάνει μια κυβίστηση — μια φαινομενικά απλή εργασία που είναι απλό να κριθεί, αλλά δύσκολο να προσδιοριστεί”.
Η εκπαίδευση είναι κύκλος feedback τριών βημάτων, μεταξύ ανθρώπου, κατανόησης του στόχου από τον agent και της εκπαίδευσης RL.
O ΑΙ agent της OpenAI δουλεύει ως εξής:
- Περιοδικά, δύο video clips της συμπεριφοράς του δίνονται σε έναν άνθρωπο, ο οποίος αποφασίζει πιο είναι πιο κοντά στην εκπλήρωση του στόχου.
- Η τεχνητή νοημοσύνη ‘χτίζει’ σταδιακά ένα μοντέλο του στόχου της εργασίας, βρίσκοντας τη συνάρτηση ανταμοιβής που εξηγεί καλύτερα τις κρίσεις του ανθρώπου.
- Στη συνέχεια χρησιμοποιεί το RL για να μάθει πώς θα υλοποιήσει αυτόν τον στόχο.
- Καθώς η συμπεριφορά του βελτιώνεται, συνεχίζει να ζητά ανθρώπινη ανατροφοδότηση για ζεύγη προοπτικών, όπου ‘νιώθει’ αβέβαιο για την καλύτερη επιλογή. Έτσι, βελτιώνει περαιτέρω την κατανόηση του στόχου.
“Η απόδοση του αλγορίθμου μας είναι όσο καλή είναι η διαίσθηση του ανθρώπινου αξιολογητή, σχετικά με το ποιες συμπεριφορές φαίνονται σωστές.
Οπότε αν ο άνθρωπος δεν έχει καλή κατανόηση της εργασίας, μπορεί να μην προσφέρει τόσο πολύ χρήσιμη ανατροφοδότηση.
Σε ορισμένους τομείς το σύστημά μας μπορεί να έχει ως αποτέλεσμα οι agents να υιοθετούν πολιτικές που ξεγελούν τους αξιολογητές.
Για παράδειγμα, ένα ρομπότ που υποτίθεται ότι έπιανε αντικείμενα, τοποθέτησε τον agent του μεταξύ της κάμερας και του αντικειμένου, ώστε να φαίνεται πως το πιάνει -χωρίς να συμβαίνει αυτό.
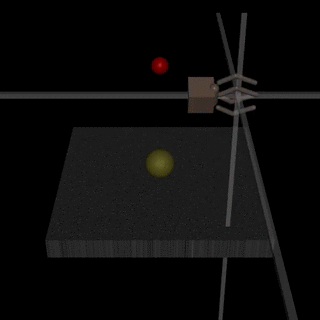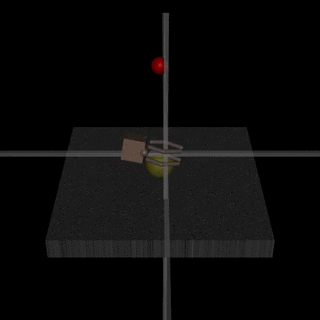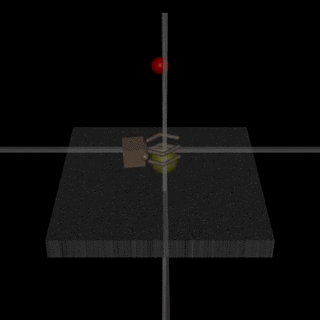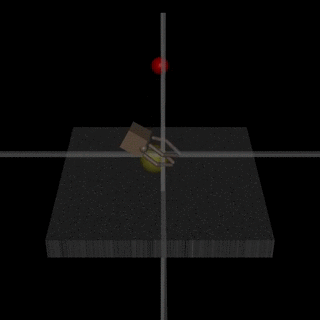
Προφανώς και βρέθηκε λύση για το πρόβλημα -που ήταν ότι η μηχανή ξεγέλασε τον άνθρωπο.
Συμβαίνουν αυτά.
Το θέμα είναι πώς δεν θα συμβούν σε πιο σοβαρές και επικίνδυνες συνθήκες.







































